El aprendizaje automático reduce radicalmente la carga de trabajo del recuento de células para el diagnóstico de enfermedades
El uso del aprendizaje automático para realizar recuentos de células sanguíneas para el diagnóstico de enfermedades en lugar de máquinas analizadoras de células, caras y a menudo menos precisas, ha sido, sin embargo, muy laborioso, ya que requiere una enorme cantidad de trabajo de anotación manual por parte de humanos en el entrenamiento del modelo de aprendizaje automático. Sin embargo, investigadores de la Universidad de Benihang han desarrollado un nuevo método de entrenamiento que automatiza gran parte de esta actividad.

Los resultados de los recuentos de células comparados con los resultados de los recuentos predichos mostraron que el nuevo método de entrenamiento desarrollado permite que el aprendizaje automático cuente con mayor precisión las células sanguíneas
Cyborg and Bionic Systems
Su nuevo esquema de entrenamiento se describe en un artículo publicado en la revista Cyborg and Bionic Systems el 9 de abril.
El número y el tipo de células de la sangre suelen desempeñar un papel crucial en el diagnóstico de enfermedades, pero las técnicas de análisis celular utilizadas habitualmente para realizar ese recuento de células sanguíneas -que implican la detección y medición de las características físicas y químicas de las células suspendidas en el fluido- son caras y requieren preparaciones complejas. Y lo que es peor, la precisión de las máquinas de análisis celular es de sólo un 90 por ciento, debido a diversas influencias como la temperatura, el pH, el voltaje y el campo magnético que pueden confundir al equipo.
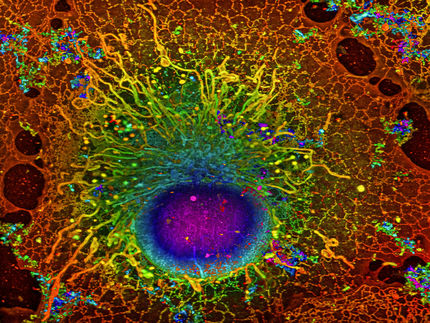
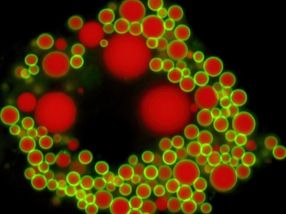
Para mejorar la precisión, reducir la complejidad y disminuir los costes, últimamente se ha investigado mucho sobre las alternativas al uso de programas informáticos para realizar la "segmentación" de las fotografías de la sangre tomadas por una cámara de alta definición conectada a un microscopio. La segmentación implica algoritmos que realizan un etiquetado píxel a píxel de lo que aparece en una foto, en este caso, qué partes de la imagen son células y cuáles no; en esencia, contar el número de células en una imagen.
En el caso de las imágenes en las que sólo aparece un tipo de célula, estos métodos alcanzan un nivel de precisión decente, pero no funcionan bien cuando se enfrentan a imágenes con múltiples tipos de células. Por eso, en los últimos años, los investigadores han intentado resolver el problema recurriendo a las redes neuronales convolucionales (CNN), un tipo de aprendizaje automático que refleja la estructura de conexiones de la corteza visual humana.
Para que la CNN pueda realizar esta tarea, primero debe ser "entrenada" para entender qué es y qué no es una célula en muchos miles de imágenes de células que los humanos han etiquetado manualmente. A continuación, cuando se le presenta una nueva imagen sin etiquetar, reconoce y puede contar las células que contiene.
"Pero ese etiquetado manual es laborioso y caro, incluso cuando se hace con la ayuda de expertos", explica Guangdong Zhan, coautor del artículo y profesor del Departamento de Ingeniería Mecánica y Automatización de la Universidad de Beihang, "lo que desvirtúa el propósito de una alternativa que se supone más sencilla y barata que los analizadores de células".
Así que los investigadores de la Universidad de Beihang desarrollaron un nuevo esquema para entrenar la CNN, en este caso, U-Net, un modelo de segmentación de red totalmente convolucional que ha sido ampliamente utilizado en la segmentación de imágenes médicas desde que se desarrolló por primera vez en 2015.
En el nuevo esquema de entrenamiento, la CNN se entrena primero en un conjunto de muchos miles de imágenes con un solo tipo de células (tomadas de la sangre de ratones).
Estas imágenes de un solo tipo de célula se "preprocesan" automáticamente mediante algoritmos convencionales que reducen el ruido en las imágenes, mejoran su calidad y detectan los contornos de los objetos en la imagen. A continuación, realizan una segmentación adaptativa de la imagen. Este último algoritmo calcula los distintos niveles de gris de una imagen en blanco y negro, y si una parte de la imagen se encuentra más allá de un determinado umbral de gris, el algoritmo la segmenta como un objeto distinto. Lo que hace que el proceso sea adaptativo es que, en lugar de segmentar partes de la imagen según un umbral de gris fijo, lo hace según las características locales de la imagen.
Después de presentar el conjunto de entrenamiento de un solo tipo de célula al modelo U-Net, el modelo se ajusta utilizando un pequeño conjunto de imágenes anotadas manualmente de múltiples tipos de células. En comparación, se mantiene una cierta cantidad de anotaciones manuales, y el número de imágenes necesarias para ser etiquetadas por humanos se reduce de lo que antes eran muchos miles a sólo 600.
Para probar su esquema de entrenamiento, los investigadores utilizaron primero un analizador de células tradicional en las mismas muestras de sangre de ratón para realizar un recuento de células independiente con el que poder comparar su nuevo enfoque. Comprobaron que la precisión de su esquema de entrenamiento en la segmentación de imágenes de tipo celular múltiple era del 94,85 por ciento, el mismo nivel que se lograba entrenando con imágenes de tipo celular múltiple anotadas manualmente.
La técnica también puede aplicarse a modelos más avanzados para considerar problemas de segmentación más complejos.
Dado que la nueva técnica de entrenamiento todavía implica cierto nivel de anotación manual, los investigadores esperan seguir desarrollando un algoritmo totalmente automático para anotar y entrenar modelos.
Nota: Este artículo ha sido traducido utilizando un sistema informático sin intervención humana. LUMITOS ofrece estas traducciones automáticas para presentar una gama más amplia de noticias de actualidad. Como este artículo ha sido traducido con traducción automática, es posible que contenga errores de vocabulario, sintaxis o gramática. El artículo original en Inglés se puede encontrar aquí.
Publicación original

Más noticias del departamento ciencias