La IA predice la función de las enzimas
Este método ofrece una amplia gama de aplicaciones potenciales
Anuncios


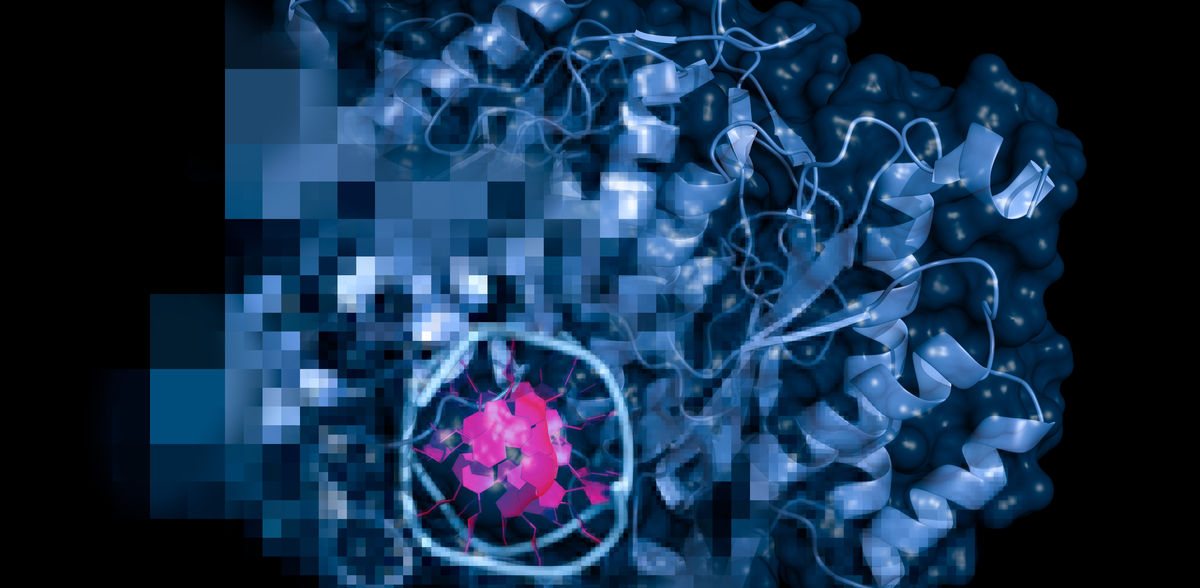
Las enzimas son las fábricas de moléculas de las células biológicas. Sin embargo, a menudo se desconoce qué componentes moleculares básicos utilizan para ensamblar moléculas diana, y resulta difícil medirlos. Un equipo internacional de bioinformáticos de la Universidad Heinrich Heine de Düsseldorf (HHU) ha dado un paso importante en este sentido: Su método de IA predice con un alto grado de precisión si una enzima puede funcionar con un sustrato específico. Ahora presentan sus resultados en la revista científica Nature Communications.
Las enzimas son importantes biocatalizadores en todas las células vivas: Facilitan las reacciones químicas, a través de las cuales se producen todas las moléculas importantes para el organismo a partir de sustancias básicas (sustratos). La mayoría de los organismos poseen miles de enzimas diferentes, cada una de las cuales es responsable de una reacción muy específica. La función colectiva de todas las enzimas conforma el metabolismo y proporciona así las condiciones para la vida y la supervivencia del organismo.
Aunque los genes que codifican enzimas pueden identificarse fácilmente como tales, la función exacta de la enzima resultante se desconoce en la inmensa mayoría de los casos (más del 99%). Esto se debe a que las caracterizaciones experimentales de su función -es decir, qué moléculas iniciales convierte una enzima específica en qué moléculas finales concretas- llevan muchísimo tiempo.

Junto con colegas de Suecia y la India, el equipo de investigación dirigido por el profesor Dr. Martin Lercher, del grupo de investigación de Biología Celular Computacional de la HHU, ha desarrollado un método basado en IA para predecir si una enzima puede utilizar una molécula específica como sustrato para la reacción que cataliza.
Profesor Lercher: "La particularidad de nuestro modelo ESP ("Enzyme Substrate Prediction") es que no nos limitamos a enzimas individuales y especiales y a otras estrechamente relacionadas con ellas, como ocurría con modelos anteriores. Nuestro modelo general puede funcionar con cualquier combinación de una enzima y más de 1.000 sustratos distintos".
El estudiante de doctorado Alexander Kroll, autor principal del estudio, ha desarrollado un modelo denominado de aprendizaje profundo en el que la información sobre enzimas y sustratos se codificó en estructuras matemáticas conocidas como vectores numéricos. Los vectores de unos 18.000 pares enzima-sustrato validados experimentalmente -en los que se sabe que la enzima y el sustrato trabajan juntos- se utilizaron como entrada para entrenar el modelo de Aprendizaje Profundo.
Alexander Kroll: "Después de entrenar el modelo de esta manera, lo aplicamos a un conjunto de datos de prueba independiente en el que ya conocíamos las respuestas correctas. En el 91% de los casos, el modelo predijo correctamente qué sustratos coinciden con qué enzimas."
Este método ofrece una amplia gama de aplicaciones potenciales. Tanto en la investigación farmacológica como en la biotecnología es de gran importancia saber qué sustancias pueden ser convertidas por las enzimas. El profesor Lercher: "Esto permitirá a la investigación y a la industria reducir un gran número de posibles pares a los más prometedores, que luego podrán utilizar para la producción enzimática de nuevos fármacos, sustancias químicas o incluso biocombustibles".
Kroll añade: "También permitirá crear modelos mejorados para simular el metabolismo de las células. Además, nos ayudará a comprender la fisiología de diversos organismos, desde las bacterias hasta las personas".
Junto a Kroll y Lercher, también participaron en el estudio el profesor Dr. Martin Engqvist, de la Universidad Tecnológica Chalmers de Gotemburgo (Suecia), y Sahasra Ranjan, del Instituto Indio de Tecnología de Bombay. Engqvist ayudó a diseñar el estudio, mientras que Ranjan implementó el modelo que codifica la información enzimática introducida en el modelo general desarrollado por Kroll.
Nota: Este artículo ha sido traducido utilizando un sistema informático sin intervención humana. LUMITOS ofrece estas traducciones automáticas para presentar una gama más amplia de noticias de actualidad. Como este artículo ha sido traducido con traducción automática, es posible que contenga errores de vocabulario, sintaxis o gramática. El artículo original en Inglés se puede encontrar aquí.
Publicación original




Más noticias del departamento ciencias































